

Introduction#
Si vous travaillez au quotidien avec Kubernetes et que vous maintenez l’infrastructure sous-jacente, vous connaissez sans doute le défi que représente la gestion du cycle de vie, notamment les mises à jour quasi-mensuelles.
Si le déploiement initial et la création d’un cluster ne posent pas de problème car de nombreuses solutions existent (par exemple : kubespray), c’est souvent lors de l’exploitation au jour le jour (le fameux Day 2) que les choses se compliquent, particulièrement dans des environnements hybrides avec des méthodes de déploiement différentes.
Maintenir une flotte de clusters de la même manière (qui n’a jamais rêvé d’avoir un seul CNI et CSI ?), quelle que soit l’infrastructure sous-jacente, à jour et sans perdre en termes de résilience, demande une rigueur continue. C’est pourquoi, on conseille souvent de se diriger vers des solutions dites managées notamment sur le Cloud par excès de facilité où une partie des ressources (en l’occurrence les Control Planes) sont gérées par le fournisseur.
Une question se pose alors : est-ce réellement possible d’avoir une approche déclarative, totalement automatisée tout en suivant l’approche GitOps, mais surtout en restant maître des choix techniques peu importe l’endroit ?
C’est précisément là que Cluster API (souvent nommé CAPI) entre en jeu. Plus qu’un simple outil de déploiement, c’est une des réponses de la communauté Kubernetes que je qualifie de “native” grâce à sa philosophie très proche de celle d’un Pod dont on parlera un peu plus tard, notamment pour répondre à ce besoin d’automatisation et de standardisation multi-plateforme.
Prêt à plonger dans les entrailles de cet outil ? C’est parti !
Cet article est la première partie d’une série dédiée à Cluster API. Il se concentre sur les concepts fondamentaux et l’architecture globale. Par la suite, l’idée sera de déployer un premier cluster, mais surtout de mettre les mains dans le cambouis !
La philosophie et les concepts clés#
Un cluster Kubernetes pour les gouverner tous !#
Avant de détailler la mécanique interne, il convient de situer brièvement le projet. Cluster API est un outil open source hébergé par la Cloud Native Computing Foundation (CNCF). Il est développé et maintenu par le groupe d’intérêt spécialisé dans le cycle de vie des clusters (SIG Cluster Lifecycle) au sein de la communauté Kubernetes. Le projet rassemble un grand nombre de contributeurs depuis pas mal d’années, ce qui garantit une certaine maturité du produit, tout en assurant sa pérennité et sa stabilité pour des environnements de production.
Côté fonctionnement, Cluster API repose sur une idée simple : utiliser un cluster Kubernetes, appelé Management cluster, pour piloter le cycle de vie d’autres clusters, nommés Workload clusters. Ce mécanisme fonctionne grâce à l’utilisation de Custom Resource Definitions (CRDs) qui seront présentées plus tard, mais aussi grâce à l’utilisation de boucles de réconciliation.
Ainsi, on utilise l’orchestrateur Kubernetes pour provisionner et gérer l’infrastructure d’autres clusters.
Gérer ses clusters comme on gère des Pods#
Juste au-dessus, on a évoqué la boucle de réconciliation pour notamment gérer l’infrastructure. Vous savez, ce même mécanisme qui, lors de la création d’un Deployment, va gérer le cycle de vie des Pods entre ce que vous avez défini (replicas, image, etc.), appelé aussi l’état désiré, et ce qui existe dans le cluster, c’est-à-dire l’état courant. Cette boucle n’a qu’un seul objectif : faire que l’état désiré soit ce qui s’exécute au sein de votre cluster.
Pour cela, les Pods ne sont pas “mis à jour” comme on ferait un apt upgrade sur une machine virtuelle Debian. En effet, un Pod avec les nouvelles caractéristiques définies (par exemple, une nouvelle version d’image) sera créé et l’ancien supprimé si et seulement si ce nouveau Pod fonctionne correctement.
C’est exactement la même chose avec Cluster API : des ressources comme des machines virtuelles seront des objets Kubernetes qui seront supervisés par une boucle de réconciliation pour faire en sorte que les caractéristiques définies soient celles de l’infrastructure courante (CPU, mémoire, espace disque, etc.).
Par défaut, les machines virtuelles ne sont pas patchées, mais suivent la même logique que les Pods : une nouvelle sera créée et la plus ancienne supprimée. Vous l’aurez compris, CAPI épouse parfaitement la manière séquentielle de faire des mises à jour (rolling updates).
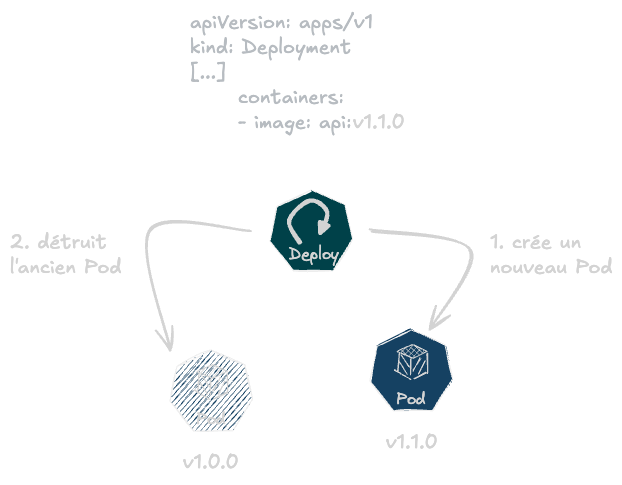
La boucle de réconciliation de Kubernetes en action au sein d’un Deployment
Le petit point Architecture !#
Le modèle d’architecture repose sur une séparation claire des rôles :
Le Management cluster agit comme le cerveau du système. Il héberge les composants et les contrôleurs de Cluster API, et c’est en son sein que l’on déclare la configuration désirée des autres clusters.
Les Workload clusters sont déployés par le Management cluster. C’est sur ces clusters que les applications ou outils s’exécuteront.
Les composants sous le capot#
Cluster API peut se déployer de plusieurs manières, mais celle qui fait souvent consensus est l’utilisation de l’opérateur officiel, très facile à déployer avec Helm. Néanmoins, quelques éléments sont à arbitrer avant de se lancer dans un helm install…
Les 4 types de Providers#
Pour fonctionner, Cluster API s’appuie sur une architecture modulaire composée de plusieurs briques, appelées Providers. Chacun a un rôle bien défini dans l’écosystème :
Le Core Provider#
Le Core Provider est le cœur du système Cluster API. C’est lui qui :
Fournit les définitions de ressources personnalisées (CRDs) fondamentales de l’API, telles que
Cluster,Machine,MachineDeploymentetMachineSet;Orchestre la logique globale et fait le lien entre les différents autres providers ;
Gère le cycle de vie de haut niveau des ressources, s’assurant par exemple que les ressources liées à un cluster soient supprimées en cascade lors de la suppression de ce dernier.
Le Control Plane Provider#
Le Control Plane Provider est chargé de la vie et de la configuration du cerveau de Kubernetes. Voici ses différentes tâches :
Initialise et configure les composants du Control Plane : kube-apiserver, kube-controller-manager, kube-scheduler et, dans la plupart des cas, etcd ;
Gère les certificats et les clés nécessaires pour que ces composants communiquent de manière sécurisée ;
Pilote les montées de version (upgrades) des Control Planes de manière ordonnée (par exemple, en remplaçant les machines une par une).
Le Bootstrap Provider#
Le Bootstrap Provider a pour mission de transformer une machine nue (virtuelle ou physique) en un nœud Kubernetes fonctionnel. C’est lui qui :
Génère les données de configuration au format attendu par le système d’exploitation cible (par exemple : cloud-init) ;
Prépare les scripts nécessaires pour installer les composants requis comme le moteur de conteneur (souvent containerd) et la kubelet ;
Fournit les commandes d’initialisation (par exemple :
kubeadm init) ou de jonction (kubeadm join) pour que la machine puisse s’intégrer au cluster une fois démarrée.
L’Infrastructure Provider#
L’Infrastructure Provider est l’agent de liaison avec l’environnement cible ou le fournisseur de Cloud. Celui-ci :
Communique avec l’API sous-jacente (par exemple : AWS, Azure, vSphere, Proxmox) ;
Gère la création, la modification et la suppression des ressources brutes telles que les machines virtuelles, les réseaux, les adresses IP ;
Fournit une implémentation spécifique aux objets de base de Cluster API (par exemple
AWSMachinepour une Machine générique).
Bien évidemment, il existe d’autres types de Providers, mais ces quatre-là sont les plus courants et sont requis pour le bon fonctionnement de Cluster API.
On parlera d’ailleurs dans la prochaine partie du Provider IPAM, mais je n’en dis pas plus !
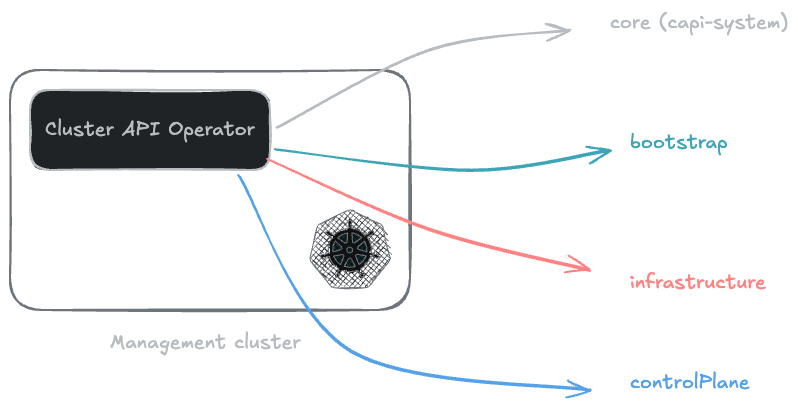
Les Providers à définir dans l’opérateur Cluster API pour le rendre fonctionnel
Le provisioning, étape par étape#
Concrètement, que se passe-t-il lorsque l’on déclenche la création d’un cluster ? Tout commence, comme souvent, avec la commande kubectl create -f cluster.yaml sur le Management cluster.
Dans ce cas-ci, le fichier cluster.yaml regroupe alors l’ensemble des ressources pour déployer le cluster dans son ensemble, celles-ci seront pleinement détaillées dans la partie 2, patience…
Dans un premier temps, le Core Provider détecte la création de la ressource Cluster. Il sollicite alors l’Infrastructure Provider pour qu’il prépare les ressources nécessaires.
Ensuite, le Control Plane Provider entre en jeu pour instancier les machines destinées, comme son nom l’indique, au Control Plane. Pour chaque machine, le Bootstrap Provider génère un script de configuration personnalisé.
Ce script est transmis à l’Infrastructure Provider, qui va demander la création de la machine virtuelle sur la plateforme cible en lui injectant cette configuration.
Au démarrage, la machine virtuelle exécute son script d’initialisation, installe les composants requis et s’enregistre auprès du premier Control Plane (s’il existe) en tant que nouveau nœud. Le même processus est ensuite répété pour les Workers via les ressources MachineDeployment.
Il y a deux points à ne pas oublier pour rendre les nœuds au statut Ready :
- Installer une couche réseau (CNI) pour permettre aux Pods de communiquer ;
- Déployer un Cloud Controller Manager pour récupérer et ajouter le champ
providerIDsur le nœud qui vient d’être créé, ce qui fait le lien avec l’infrastructure sous-jacente.
Une fois le nœud prêt, CAPI continue son processus et répétera ces opérations autant de fois que nécessaire pour atteindre l’état désiré.
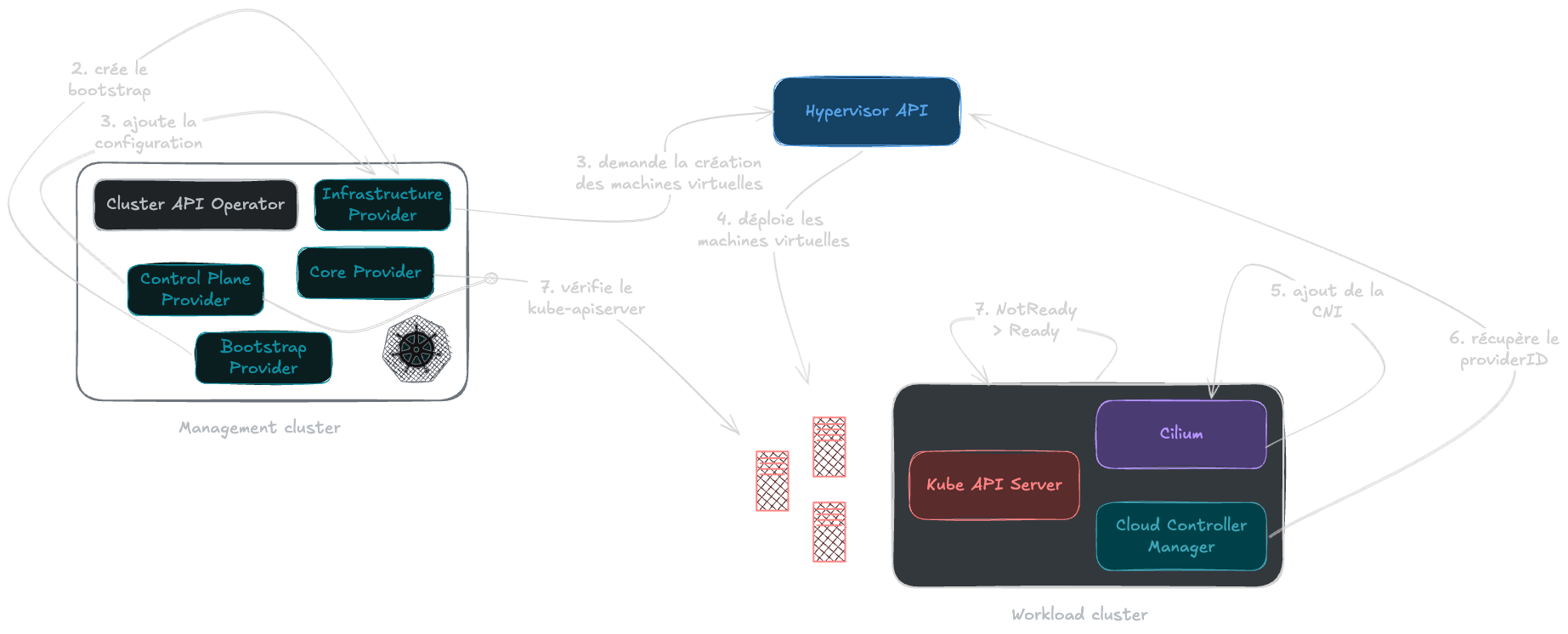
Provisioning complet d’un nouveau cluster via le cluster de Management
Pour la mise à jour, ce n’est pas bien différent. Le cycle reste le même, la différence se situe dans le fait que le nœud le plus ancien (Control Plane ou Worker) sera supprimé dès qu’un nouveau est au statut Ready.
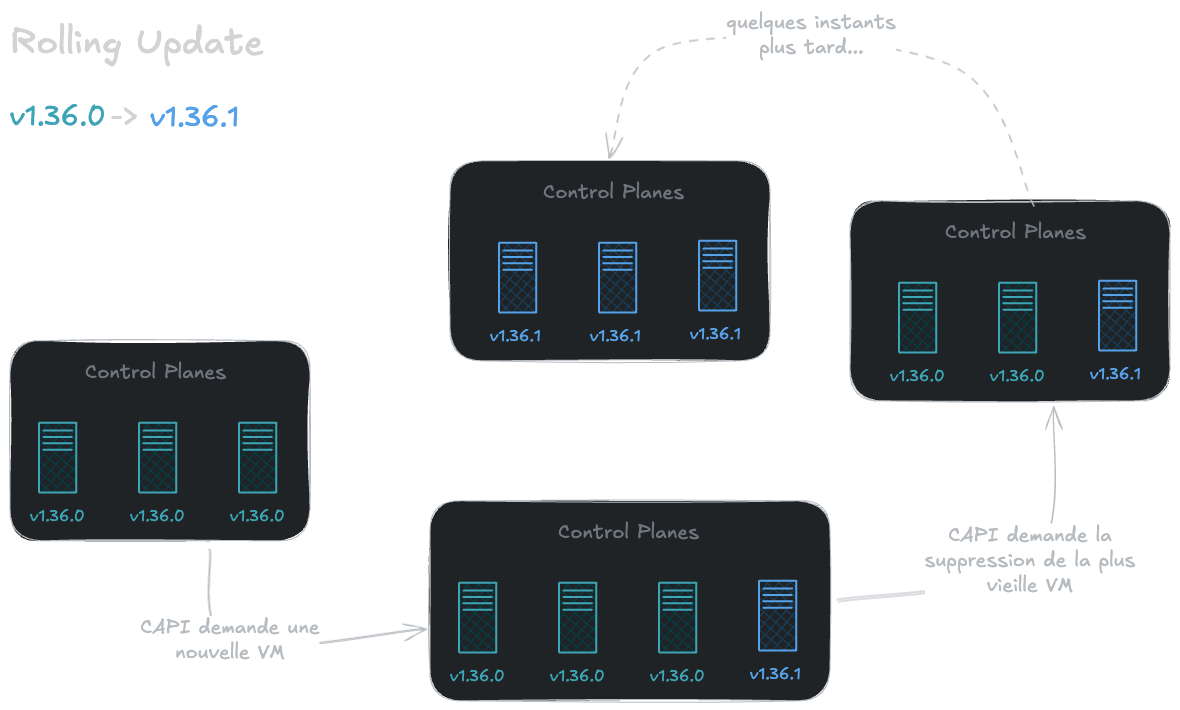
Le rolling update en action
Un air de souveraineté#
L’art du choix#
L’un des avantages majeurs de Cluster API réside dans la liberté de choix des composants.
Quelle que soit la catégorie et le Provider que vous allez choisir, un large catalogue s’offre à vous.
Si l’on prend le cas de l’Infrastructure, il y en a pour tous les goûts : CAPMOX pour Proxmox, CAPV pour vSphere, CAPZ pour Azure. Cela couvre les besoins les plus courants, même chose avec le Control Plane (et le Bootstrap) où les distributions Kubernetes les plus connues sont couvertes : kubeadm, k3s, RKE2 ou encore Talos.
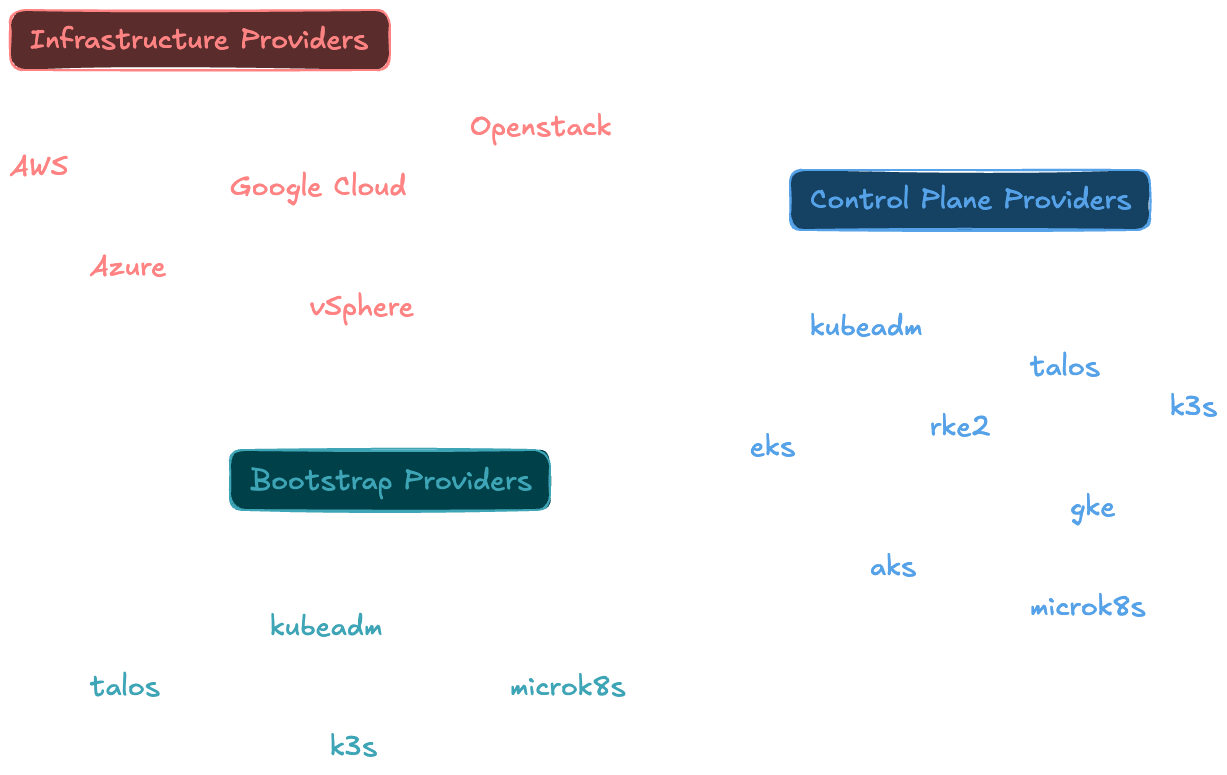
Il y en a pour tous les goûts, n’est-ce pas ? (liste non exhaustive…)
Cette approche permet de construire sa propre plateforme Kubernetes avec un très large choix de possibilités ! On peut ainsi migrer d’un hyperviseur à un autre, changer sa distribution Kubernetes, en modifiant quelques API sans pour autant changer complètement de moteur de déploiement.
Une maîtrise totale#
Deuxième buzzword tendance après l’IA : la souveraineté. On associe souvent ce mot à la nécessité d’héberger ses données dans le pays dans lequel on vit ou travaille, notamment pour bénéficier des mêmes contraintes réglementaires que le prestataire de service ou faire en sorte que les données ne quittent jamais le territoire.
Pour moi, il y a plusieurs niveaux. Le premier consiste déjà à avoir le moins d’adhérence possible avec un fournisseur d’infrastructure ou un système utilisé. En outre, cela représente la facilité de migrer d’un Cloud à l’autre ou d’une distribution Kubernetes à une autre afin d’éviter l’effet “vendor lock-in” pour conserver une certaine liberté.
Vous l’aurez compris, avec la section du dessus, Cluster API répond suffisamment à ces attentes.
Vers plus de fonctionnalités#
Le cycle de vie classique#
Historiquement, le comportement par défaut de Cluster API repose sur la stratégie de mise à jour progressive, appelée aussi rolling update. Cette approche implique la création d’une nouvelle instance puis la destruction de la machine virtuelle existante pour appliquer les changements demandés.
Bien que fonctionnelle, cette méthode pose parfois quelques défis :
Certaines charges de travail supportent difficilement le drainage des nœuds, ce qui entraîne des interruptions de service.
Des modifications mineures, comme l’ajout d’une clé SSH ou un changement sur le nombre de Go de RAM, ne justifient pas nécessairement le renouvellement complet d’une machine virtuelle.
La mise à jour sur place#
Pour pallier ces limites, une fonctionnalité majeure a été introduite : la mise à jour sur place, ou in-place upgrade avec la version v1.12. Cluster API permet désormais de mettre à jour les binaires Kubernetes, tels que la Kubelet ou les composants du Control Plane, directement au sein de la machine existante, sans la détruire.
Il est tout à fait possible de combiner la mise à jour sur place et la stratégie de mise à jour progressive. En ajustant la stratégie de déploiement, on peut définir finement le comportement souhaité en fonction du type de modification à apporter au cluster.
Les mises à niveau en chaîne#
Autre fonctionnalité très attendue, les mises à niveau en chaîne, ou chained upgrade disponible également avec la v1.12 de Cluster API, qui permet d’automatiser la mise à jour séquentielle des nœuds.
Il devient ainsi possible de passer le Control Plane d’une version 1.33.0 à une version 1.36.0 en appliquant automatiquement toutes les mises à jour mineures intermédiaires (1.33.0, 1.34.0, 1.35.0). Une fois le Control Plane à jour, c’est au tour des Workers de migrer de la version 1.33.0 à la version 1.36.0 en faisant le grand saut.
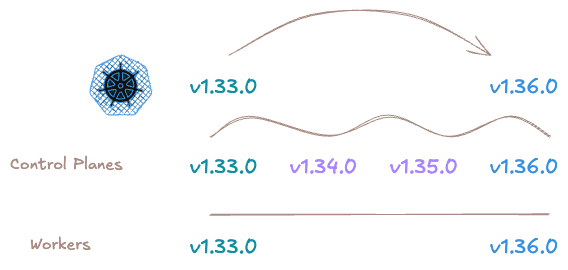
Fonctionnement des mises à niveau en chaîne avec Cluster API
Talos Linux et Cluster API, le mariage parfait#
Les limites des systèmes d’exploitation traditionnels#
Lorsque l’on déploie des nœuds Kubernetes, on utilise souvent des distributions Linux classiques comme Ubuntu, Debian ou RHEL. Bien que robustes, ces systèmes n’ont pas été conçus pour être des systèmes qui n’exécutent que des conteneurs.
En effet, la présence de SSH, de gestionnaires de paquets et de nombreux services système augmente la surface d’attaque.
De plus, ces systèmes sont sujets à la dérive de configuration : au fil du temps, des modifications manuelles ou des mises à jour partielles rendent chaque nœud unique, ce qui s’oppose à l’immuabilité recherchée dans un environnement Kubernetes.
Rappelez-vous, on cherche réellement à mettre à jour les machines comme on met à jour des Pods !
Le paradigme de Talos Linux#
Talos Linux propose un changement de paradigme. C’est un système d’exploitation immuable, minimaliste et sécurisé par défaut, dont l’unique but est de faire fonctionner Kubernetes.
Il se distingue notamment par plusieurs caractéristiques :
- Absence de shell et d’accès SSH ;
- Aucun gestionnaire de paquets ;
- Système de fichiers racine en lecture seule ;
- Configuration et gestion exclusivement via une API et un fichier YAML avec la commande
talosctl; - Une usine d’images en fonction de la plateforme ou des plugins à incorporer, car oui, il est possible d’ajouter des composants supplémentaires comme gVisor, les vmtools pour VMware ou encore le QEMU agent.
Cet OS est donc votre meilleur allié car il répond à énormément de critères en termes de sécurité. De plus, son approche pensée “as-code” le rend terriblement pratique à configurer…
L’adéquation avec Cluster API#
Avec Cluster API et l’approche “as-code” de Talos Linux, la configuration du système d’exploitation (réseau, montages de disques, paramètres noyau) devient une ressource déclarative Kubernetes au sein du Management cluster, le TalosConfigTemplate.
Ainsi, l’infrastructure, l’OS et les applications sont pilotés par le même moteur de réconciliation, de façon totalement unifiée.
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha3
kind: TalosConfigTemplate
metadata:
name: talos-worker
spec:
template:
spec:
generateType: worker
talosVersion: v1.13.2
strategicPatches:
- |
machine:
network:
nameservers:
- 10.10.1.100
- 10.10.1.101
interfaces:
- deviceSelector:
busPath: "0*"
dhcp: true
install:
disk: /dev/sda
extraKernelArgs:
- net.ifnames=0
cluster:
controlPlane:
endpoint: https://10.1.0.10:6443Exemple ici avec des caractéristiques réseau que l’on souhaite propager aux Workers
Quelques mots pour conclure#
En standardisant la gestion du cycle de vie des clusters, Cluster API apporte la flexibilité d’un modèle unifié avec un très large catalogue aussi bien en termes d’infrastructure que de distribution Kubernetes. Que l’on utilise Proxmox, vSphere, Azure, ou encore Google Cloud, l’expérience opérationnelle reste identique, ce qui réduit clairement la complexité des opérations.
Néanmoins, une question reste en suspens : si Cluster API a besoin d’un cluster Kubernetes pour créer d’autres clusters, comment peut-on créer ce premier cluster de Management ?
Bien évidemment, on répondra à cette question dans le prochain chapitre ! Il traitera de l’initialisation du Management cluster, piloté par Cluster API avec Proxmox et Talos Linux.
À très vite !


