

Les limites de Kubernetes#
Kubernetes s’est globalement imposé et a modifié la manière dont on opère aujourd’hui les applications conteneurisées. Comme je l’ai déjà décrit à travers plusieurs de mes articles, ce dernier offre des mécanismes avancés pour orchestrer des conteneurs, mais aussi, les exposer à travers des Services, Ingress ou encore plus récemment sous forme de Routes via la Gateway API.
Mais derrière ce fonctionnement, se cache un modèle réseau volontairement très simple et permissif : tous les Pods peuvent communiquer entre eux sans restriction, peu importe leur namespace comme cela est décrit dans le Kubernetes networking model.
Ce choix de conception a un avantage évident : faciliter la mise en place d’applications ou d’outils dans des environnements de développement et réduire la complexité initiale. Mais en production, cela représente rapidement un problème majeur rien qu’en termes de sécurité. Par exemple, dans le cas d’un cluster partagé entre plusieurs équipes ou hébergeant des composants critiques, rien n’empêche un Pod compromis ou mal configuré de scanner le réseau ou d’accéder à des services internes qui ne devraient pas être exposés.
Kubernetes propose un mécanisme pour pallier à cela : l’objet NetworkPolicy. Celui-ci permet de restreindre les flux réseau en autorisant uniquement certaines communications, mais ces dernières opèrent uniquement à la couche 3 et 4 du modèle OSI, c’est-à-dire sur des IPs et/ou des ports.
La NetworkPolicy est avant tout un objet pensé pour le développeur qui souhaite déployer son application dans Kubernetes dans un namespace en particulier : elle offre un mécanisme basé sur des labels (namespaces ou Pods) ou encore sur des plages d’adresses IP. Cela reste assez limitant et ne permet pas de filtrer sur un chemin d’API ou sur la méthode REST qui appelle votre application.
Dans le cas où l’on souhaiterait chiffrer systématiquement les communications entre Pods pour éviter d’avoir du trafic en clair, cela représente un défi colossal… Imaginez les différentes étapes : génération des certificats, rotation automatique, déploiement de ces derniers au sein des Pods. Autant d’opérations qui deviennent rapidement ingérables à l’échelle d’un cluster avec des dizaines, voire des centaines de microservices sans oublier un risque d’erreur très important.
Enfin, un point qu’on laisse souvent de côté : l’observabilité. Avoir une vue d’ensemble de son réseau, c’est important pour comprendre et diagnostiquer les potentiels soucis tels que les timeouts, les codes d’erreur HTTP ou encore les flux qui sont bloqués.
Le Service Mesh, la solution#
Vous l’aurez compris, la réponse aux problématiques évoquées ci-dessus a un nom : le Service Mesh.
Dans Kubernetes, un Service Mesh est une couche d’infrastructure qui se place entre vos charges de travail et le réseau. Il est chargé d’intercepter, sécuriser, observer et gérer les communications entre les Pods.
Ce concept a un avantage crucial : il n’est pas nécessaire de modifier le code applicatif ! Il devient donc possible de bénéficier d’un ensemble de fonctionnalités sans modification des applications.
En parlant de fonctionnalités, voici celles que l’on retrouve principalement quand on parle de ce type d’outil :
Mise en place de politiques de sécurité : Le Service Mesh permet de définir et d’appliquer diverses règles sur l’ensemble des services. Par exemple : des quotas, des limitations de débit, de l’authentification ou des accès demandant des autorisations spécifiques ;
Résilience et tolérance aux pannes : Lorsqu’un service devient indisponible ou répond lentement, le Service Mesh dispose de différentes fonctionnalités : il automatise les retries et les fallbacks, et peut rediriger le trafic vers d’autres instances disponibles dans l’unique but de préserver la disponibilité des applications ;
Chiffrement des communications : Le mutual TLS (mTLS) chiffre automatiquement les échanges entre Pods. Cette fonctionnalité est souvent accompagnée de mécanismes permettant de créer et renouveler les certificats à la volée sans action particulière ;
Gestion intelligente du trafic : Le Service Mesh offre des capacités avancées de routage, permettant de diriger le trafic en fonction de la charge, des versions ou même de règles spécifiques. Plusieurs stratégies peuvent être définies : le canary deployment pour rediriger une fine portion du trafic vers une nouvelle version, ou encore le mirroring des requêtes si l’on peut dupliquer le trafic à des fins de test sans impacter l’environnement concerné par exemple ;
Observabilité : Pour avoir une vue d’ensemble du trafic réseau, le Service Mesh fournit des indicateurs sous forme de métriques, logs et traces dans l’objectif d’avoir une visibilité accrue pour investiguer d’éventuelles latences, codes d’erreur HTTP, ou avoir une idée du nombre de requêtes.
En résumé, le Service Mesh offre un panel de fonctionnalités permettant d’améliorer la sécurité, d’accroître la visibilité, donner du contrôle sur la gestion du trafic sans oublier d’offrir de la résilience une fois ce dernier configuré.
En ce qui concerne les solutions proposées au sein de l’écosystème de la Cloud Native Computing Foundation, deux solutions sont au statut graduated ce qui démontre une certaine maturité et sérénité pour les déployer dans des contextes de production.
Istio est souvent considéré comme la référence : riche en fonctionnalités avancées pour la sécurité, le routage et l’observabilité. Néanmoins, ce dernier peut être complexe à configurer et à exploiter.
Linkerd se distingue par sa légèreté et sa simplicité d’installation : cette solution offre une approche minimaliste, idéale pour les équipes souhaitant un Service Mesh opérationnel avec des fonctionnalités essentielles comme le mTLS et la surveillance des services.
Istio, voyage au sein du Service Mesh#
Parmi les solutions de Service Mesh, Istio se distingue par ses nombreuses fonctionnalités et sa flexibilité de déploiement.
C’est avant tout un projet open source très impliqué dans l’écosystème CNCF et Kubernetes, que j’ai eu l’occasion de découvrir via de multiples conférences comme la KubeCon notamment à la sortie du mode Ambient.
Du point de vue de l’installation, Istio se compose d’une succession de charts Helm à déployer. L’installation via l’opérateur officiel est dépréciée depuis la version 1.23 sachant que la dernière version en date est la 1.27.1. Néanmoins, Red Hat a annoncé la création d’un Sail Operator pour continuer à déployer Istio sous cette forme, à noter qu’il n’est pas maintenu par le projet Istio lui-même.
Côté architecture, Istio est composé de deux groupes principaux :
Le control plane (Istiod) orchestre et paramètre dynamiquement les proxies du data plane, assurant la gestion centralisée des configurations de ce dernier.
Le data plane (Sidecar/Ambient) regroupe l’ensemble des proxies qui interceptent, contrôlent et dirigent toutes les communications réseau entre les Pods. Ils jouent également un rôle clé dans la télémétrie, en collectant et en rapportant des informations détaillées sur tout le trafic du Service Mesh.
Il propose deux modes de fonctionnement : le mode Sidecar, où un proxy Envoy accompagne chaque Pod, et le mode Ambient, apparu plus récemment, qui utilise un proxy par nœud du cluster. Il est évident que ces deux modes ont leur lot d’avantages et d’inconvénients, on reviendra bien évidemment plus tard dessus.
Je vous propose de détailler spécifiquement les deux méthodes en commençant par le Sidecar.
Mode historique : Sidecar#
Le mode Sidecar constitue le mode de déploiement historique d’Istio.
Dans cette approche, chaque Pod se voit associé à un conteneur supplémentaire : un proxy Envoy, qui intercepte l’intégralité du trafic entrant et sortant. Grâce à cette interception, il est possible de mettre en place des fonctionnalités avancées de la couche 4 jusqu’à la couche 7 du modèle OSI.
Avec cette méthode, cela permet de bénéficier de fonctionnalités avancées telles que le routage conditionnel, le canary deployment, le mirroring des requêtes, par exemple.
Le Sidecar apporte également une observabilité très détaillée. Les métriques, logs et traces collectées par Envoy permettent de suivre en profondeur le comportement des applications, d’analyser la latence, le taux d’erreurs et la consommation des ressources, et ainsi, détecter rapidement les anomalies au sein du réseau.
Cependant, ce lot de fonctionnalités a un coût. L’injection d’un proxy par Pod entraîne une charge additionnelle non négligeable en ressources (CPU et mémoire) et peut augmenter rapidement la complexité opérationnelle, notamment sur de très gros clusters avec de fortes volumétries de Pods où les ressources des nœuds peuvent fondre comme neige au soleil.
La consommation du proxy représente donc un des aspects à considérer avant de choisir ce mode.

Istio avec le data plane Sidecar
Les communications entre les Pods passent obligatoirement par les conteneurs Envoy avant d’être adressées au conteneur principal.
Pour injecter le Sidecar, Istio dispose d’un mécanisme d’annotations :
kubectl label namespace backend istio-injection=enabledCe qui aura pour effet d’injecter ce fameux Sidecar sur l’ensemble des Pods du namespace backend.
Nouvelle approche : Ambient#
Pourquoi Ambient ?#
Le mode Ambient introduit par Istio 1.22 en 2022 n’a pas vocation à supprimer celui du Sidecar mais à offrir une approche alternative pour pallier aux quelques exigences concernant la consommation de ressources des conteneurs Envoy sur chaque Pod.
Même si Istio Ambient est considéré comme stable tout en gardant de nombreuses fonctionnalités que ce soit sur le contrôle et la sécurité du réseau, certains points sont à considérer. Pour l’heure, le multi-cluster est tout récemment sorti en alpha.
Je vous recommande donc d’avoir un œil attentif sur les limites de ce mode et sur la comparaison entre Sidecar et Ambient pour voir si ce dernier répond à vos besoins.
Architecture#
L’architecture du data plane pour le mode Ambient repose sur deux composants principaux :
Ztunnel qui est un proxy mutualisé en mode couche 4 (TCP et UDP) déployé sur chaque nœud. Il intercepte tout le trafic entre les Pods pour assurer le chiffrement mTLS et appliquer des politiques d’accès aussi appelées AuthorizationPolicy. Contrairement au Sidecar, le proxy Ztunnel n’inspecte pas le contenu couche 7, mais garantit l’isolation réseau et la sécurisation sans déployer un conteneur supplémentaire dans chaque Pod.
Chaque charge de travail qui transite par le Ztunnel est associée avec une identité de type SPIFFE (Secure Production Identity Framework For Everyone). Cela permet d’authentifier de manière forte chaque Pod, de chiffrer les communications (mTLS) et d’assurer une communication sécurisée entre ces derniers.
Waypoint est un composant optionnel basé sur le proxy Envoy. Pourquoi optionnel ? car seul Ztunnel est nécessaire pour avoir le mode Ambient, mais vous serez privé de fonctionnalités disponibles en inspectant la couche 7 du modèle OSI comme le fait de pouvoir filtrer sur des chemins d’URL ou d’inspecter les headers d’une requête.
Ces Waypoints ont une particularité, elles sont déployées sous forme de Gateway en utilisant les CRDs de la Gateway API comme je vous avais présenté dans mon précédent article.
Cela comporte un avantage majeur, le fait de pouvoir configurer finement ces proxys pour les mettre à l’échelle en cas de besoin. Sachant que vous pouvez déployer une gateway Waypoint par namespace ou disposer d’une gateway commune cross-namespace pour éviter de surconsommer des ressources.
Il est clairement possible de configurer la gateway Waypoint uniquement quand cela fait du sens par rapport à vos charges de travail grâce à un système d’annotations.
L’avantage principal du mode Ambient réside dans la mutualisation de ces briques au sein du data plane, ce qui diminue drastiquement l’empreinte CPU et mémoire d’Istio côté cluster Kubernetes sans délaisser des fonctionnalités essentielles en termes de sécurité.

Istio avec le data plane Ambient, fonctionnement du Ztunnel
Comme dit plus haut, toutes les communications passent par le Ztunnel, même au sein d’un même nœud. C’est le cas dans ce schéma sur le worker 2. En revanche, si jamais les Pods frontend et backend sont positionnés sur des workers différents, le trafic passe par les Ztunnel de chacun des deux nœuds pour parvenir à destination.

Istio avec le data plane Ambient avec la gateway Waypoint
Comme vous pouvez le constater avec le combo Ztunnel et Waypoint, le trafic est intercepté et redirigé par le Ztunnel pour ensuite être acheminé vers la gateway Waypoint pour finalement retraverser le Ztunnel et parvenir au Pod appelé.
Installation#
Comme dit plus haut, l’installation d’Istio Ambient repose sur un ensemble de charts à déployer. Ces charts peuvent être pilotés ou non avec le CLI istioctl.
- base : pour les différents CRDs propres à Istio ;
- istiod : pour déployer le control plane ;
- cni : pour initialiser la couche réseau d’Istio, cette dernière est compatible avec toutes les Container Network Interface (CNI) du marché ;
- ztunnel : pour installer un proxy par nœud du cluster Kubernetes ;
- gateway : optionnel mais indispensable dans le cas du déploiement des Waypoints et donc, pour profiter des fonctionnalités de la couche 7.
À noter que lors de l’installation, les charts istiod et cni doivent être initialisés avec comme values profile: ambient.
Une fois les composants déployés, là aussi, l’interception du trafic s’effectue avec un mécanisme d’annotations qui peuvent être portées sur un namespace :
kubectl label namespace backend istio.io/dataplane-mode=ambientPour bénéficier du composant Waypoint, d’autres annotations sont à disposer :
# "waypoint" doit être remplacé par le nom de votre gateway
kubectl label namespace backend istio.io/use-waypoint=waypoint
# À ajouter si les Waypoints sont dans un namespace différent de vos Pods
kubectl label namespace backend istio.io/use-waypoint-namespace=istio-systemVisibilité avec Kiali#
Kiali est un tableau de bord open source conçu spécifiquement pour Istio. Il fournit une vue graphique du Service Mesh en exposant la topologie des services et Pods, leurs interactions et leurs dépendances. Concrètement, Kiali consomme les métriques collectées par Prometheus et les traces provenant d’Istio, puis les corrèle pour créer des graphiques relatant l’ensemble du trafic réseau pour un ou plusieurs namespaces donnés.
L’utilisation de Kiali devient rapidement indispensable dès qu’un Service Mesh atteint plusieurs dizaines de charges de travail. En effet, si les proxys Ztunnel et Envoy génèrent déjà des données riches (latence, taux d’erreur, volume de trafic), leur analyse brute reste complexe.
Kiali fournit une visualisation temps réel des flux : il permet par exemple de vérifier le trafic entre services, d’identifier des erreurs HTTP entre deux composants, ou de repérer immédiatement une montée en latence sur une requête donnée.
Kiali est donc l’outil de visualisation par excellence quand on choisit de déployer Istio.
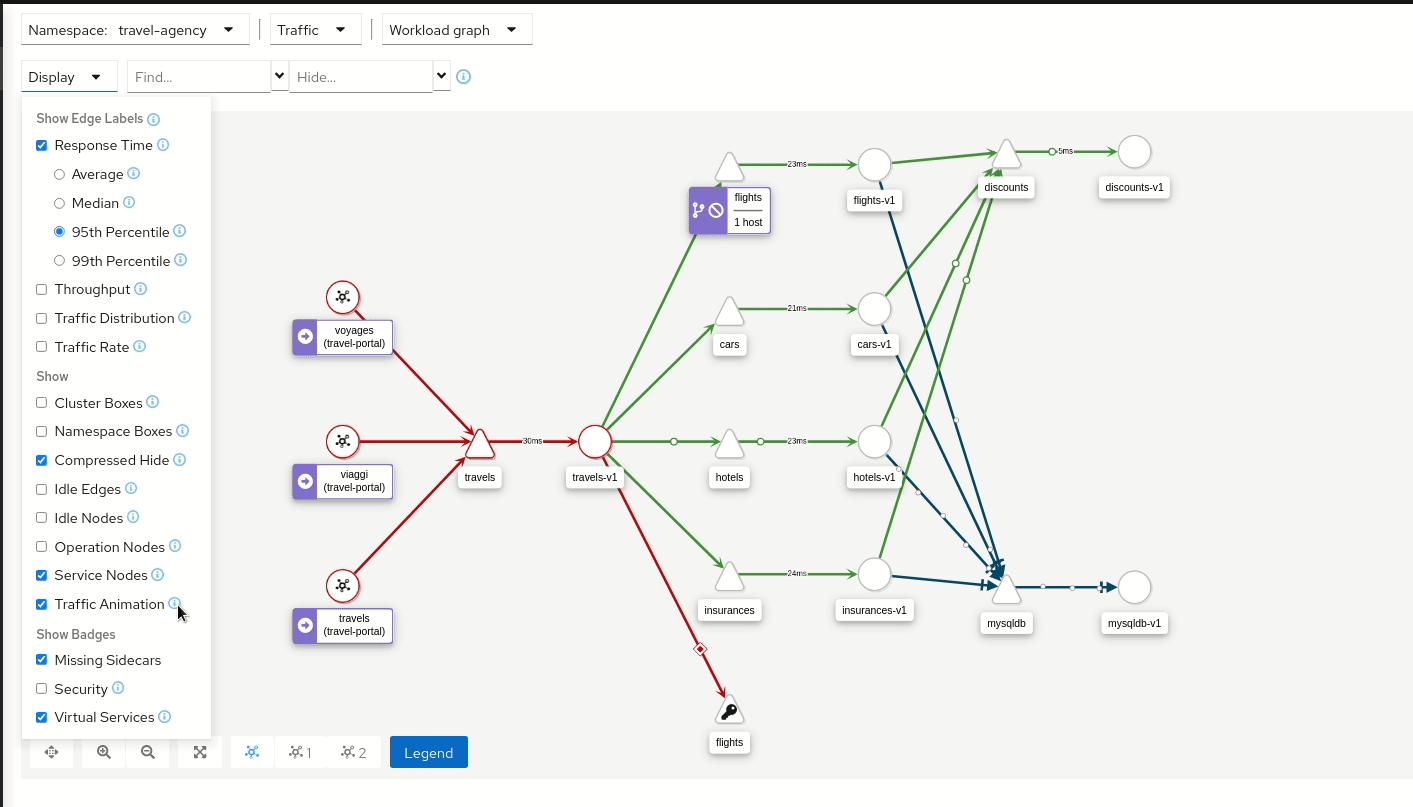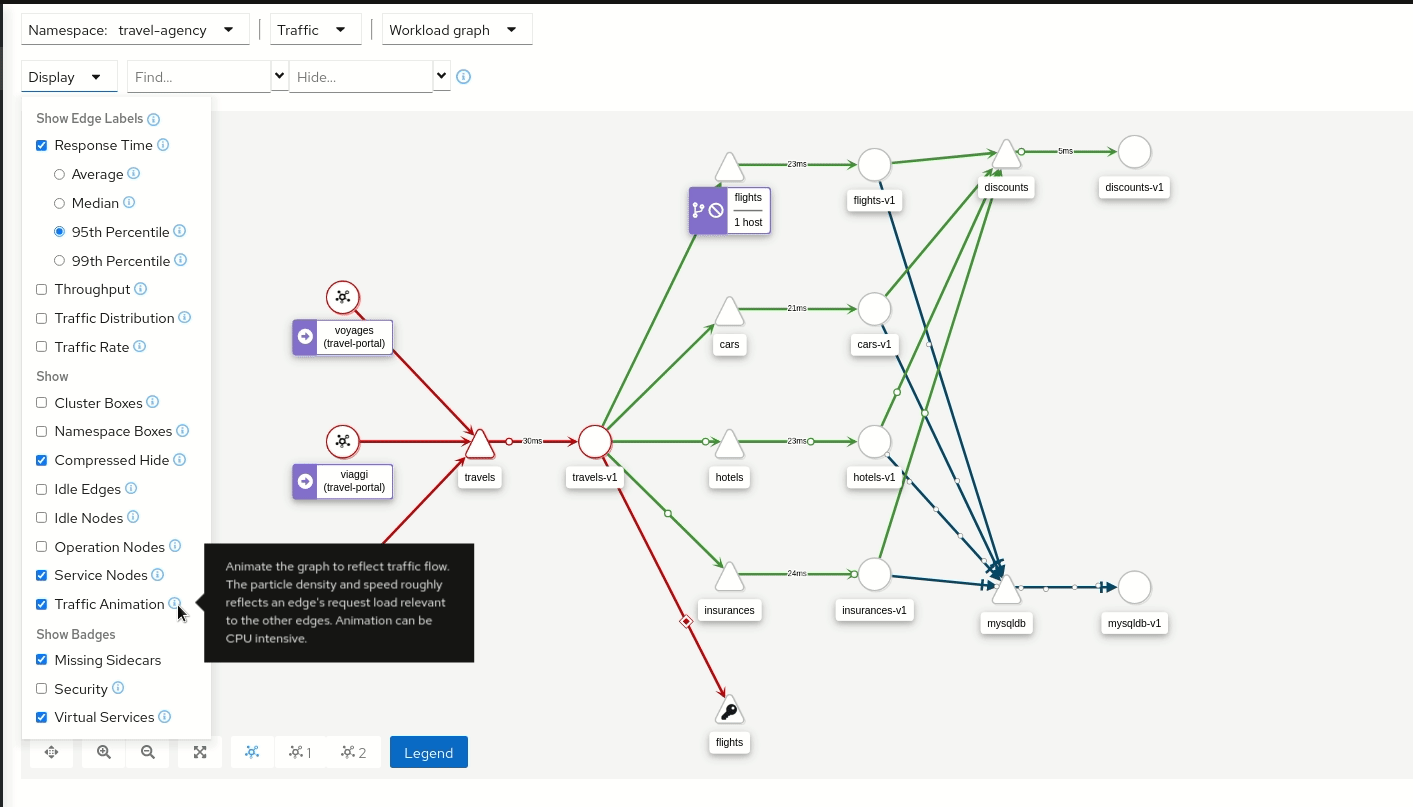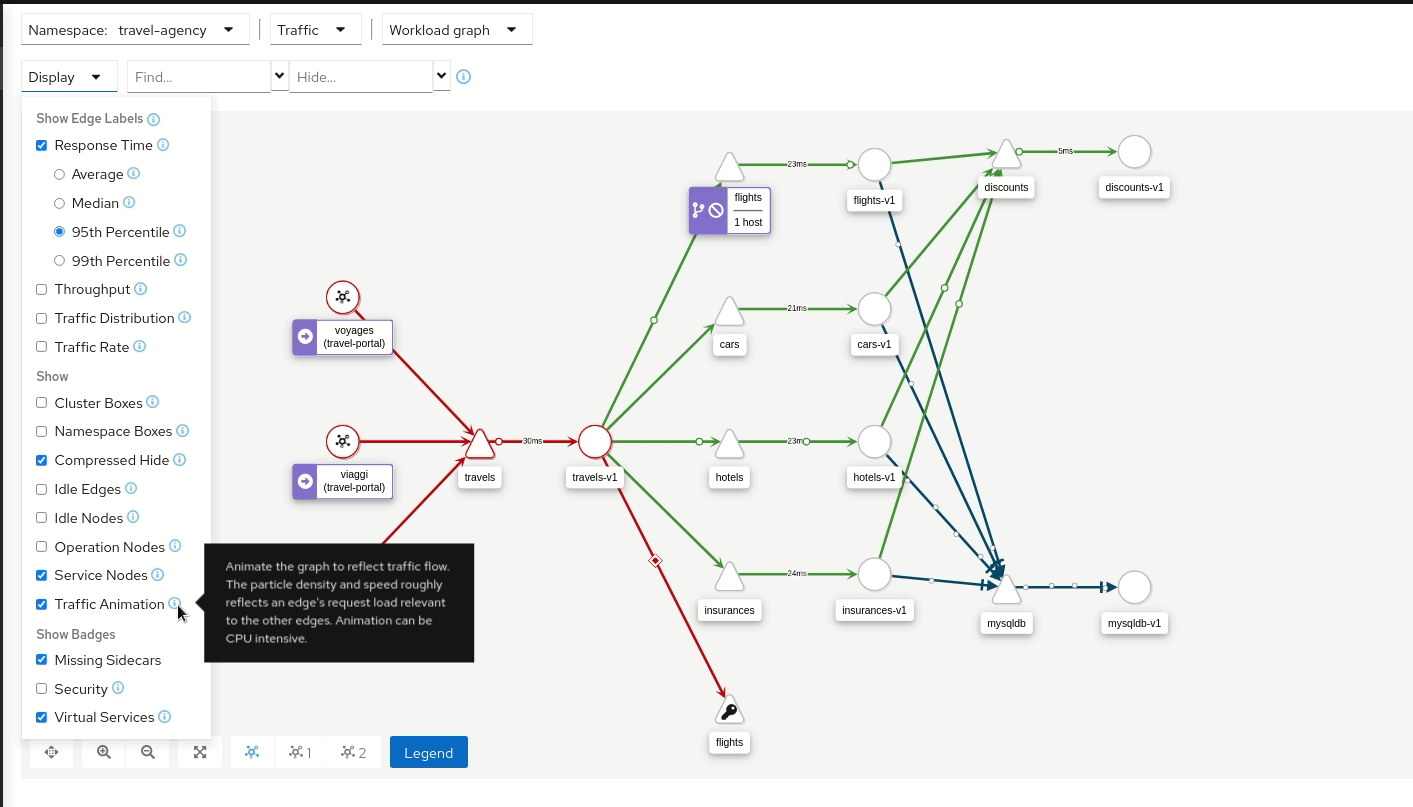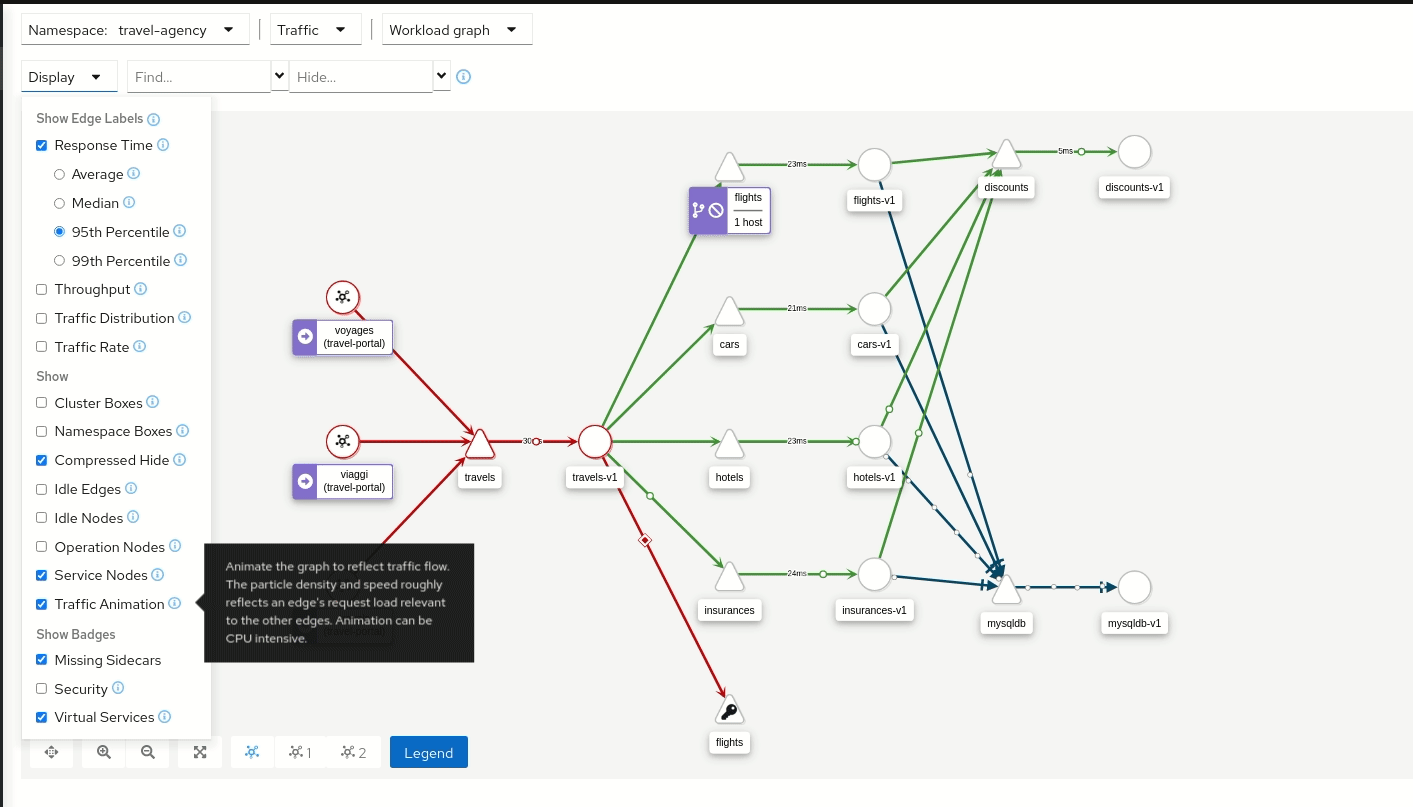
Kiali en action (image provenant de kiali.io)
La sécurité avec Istio#
La sécurité est l’un des bénéfices du Service Mesh, c’est pourquoi Istio offre un ensemble de mécanismes permettant de chiffrer, authentifier, et contrôler les communications entre vos applications dans l’objectif d’adopter les principes du Zero Trust.
Forcer le mTLS#
Une fois Istio déployé et configuré, quel que soit le mode choisi, le mTLS s’effectue de manière transparente. Il est recommandé d’appliquer un objet appelé PeerAuthentication pour forcer le chiffrement du trafic en mTLS par namespace :
apiVersion: security.istio.io/v1
kind: PeerAuthentication
metadata:
name: mtls
namespace: backend
spec:
mtls:
mode: STRICTOu sur une charge de travail donnée, représentée avec le label app: backend :
apiVersion: security.istio.io/v1
kind: PeerAuthentication
metadata:
name: mtls
namespace: workloads
spec:
selector:
matchLabels:
app: backend
mtls:
mode: STRICTAuthorizationPolicy et Zero Trust#
Pour aller plus loin que la NetworkPolicy de Kubernetes, Istio fournit une ressource personnalisée appelée AuthorizationPolicy. Ces dernières ont un avantage énorme : elles peuvent contrôler les flux d’entrée à travers un mécanisme d’identité basé sur les comptes de service Kubernetes et vont beaucoup plus loin que le filtrage sur labels et IPs.
Grâce à cet objet, il est également possible de filtrer les communications sur la couche 7 en spécifiant des chemins d’URL ou des méthodes REST par exemple.
Dans le cas du mode Ambient, il y a deux types d’AuthorizationPolicy :
Celles qui seront associées au Ztunnel et donc uniquement couche 4, et celles qui vont venir se greffer aux Waypoints. Ces dernières peuvent disposer de beaucoup plus de fonctionnalités.
Voici un exemple d’une politique d’accès associée au Ztunnel :
apiVersion: security.istio.io/v1
kind: AuthorizationPolicy
metadata:
name: api
namespace: backend
spec:
selector:
matchLabels:
app: api
action: ALLOW
rules:
- from:
- source:
principals:
- "cluster.local/ns/frontend/sa/website"
to:
- operation:
ports: ["8080"]Dans ce cas présent, on autorise les Pods qui portent le compte de service website au sein du namespace frontend à communiquer sur le port 8080 avec le Pod possédant le label app: api dans le namespace backend.
Le selector indique que c’est une AuthorizationPolicy qui sera adoptée par le Ztunnel uniquement et limitée à la couche 4.
Si on souhaite faire porter cette AuthorizationPolicy à une gateway Waypoint pour bénéficier de fonctionnalités avancées, la structure change :
apiVersion: security.istio.io/v1
kind: AuthorizationPolicy
metadata:
name: api
namespace: backend
spec:
targetRefs:
- kind: Service
group: ""
name: api
action: ALLOW
rules:
- from:
- source:
principals:
- "cluster.local/ns/frontend/sa/website"
to:
- operation:
ports: ["8080"]
methods: ["GET"]
paths: ["/orders"]Le selector est remplacé par targetRefs de type Service pour lier la règle au service Kubernetes du nom de l’api. Le Waypoint étant couche 7, il est possible d’ajouter des champs comme methods ou paths pour gagner en granularité et n’autoriser que le strict nécessaire.
Enfin, ces politiques permettent de choisir le type d’action désirée avec un choix assez large entre ALLOW, DENY, AUDIT et CUSTOM.
spec:
action: ALLOWPour finir, l’AuthorizationPolicy ne vise pas à remplacer la NetworkPolicy, mais à compléter les manques de cette dernière en apportant une couche de sécurité supplémentaire pour adopter une philosophie Zero Trust sur Kubernetes.
Encore plus de fonctionnalités !#
Istio ne s’arrête pas là.
Il est possible d’aller encore plus loin, notamment sur la gestion du trafic. L’intégration de la Gateway API facilite les choses et permet d’utiliser la plupart des concepts qu’Istio avait établi via ses propres CRDs.
C’est le cas du routage des requêtes, originalement disponible avec un VirtualService, celui-ci s’intègre avec une HTTPRoute en permettant de définir des poids pour chacun des backends :
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: backend
spec:
parentRefs:
- group: ""
kind: Service
name: backend
port: 8080
rules:
- backendRefs:
- name: backend-v1
port: 8080
weight: 90
- name: backend-v2
port: 8080
weight: 10Le service backend aura donc une chance sur dix d’être routé vers le backend-v2.
Il est aussi possible de faire du mirroring et dupliquer le trafic sur le backend-v2 sans impact sur le fonctionnement de l’application, là aussi avec une HTTPRoute :
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: backend
spec:
parentRefs:
- group: ""
kind: Service
name: backend
port: 8080
rules:
- filters:
- type: RequestMirror
requestMirror:
backendRef:
name: backend-v2
port: 8080
backendRefs:
- name: backend-v1
port: 8080L’idée n’étant pas de détailler toutes les possibilités, mais de démontrer qu’Istio arrive avec un panel de fonctionnalités qui sont peu à peu intégrées au standard de la Gateway API ce qui prouve la position influente de ce dernier.
Conclusion#
Le Service Mesh s’impose aujourd’hui comme un composant essentiel pour toute entreprise souhaitant opérer des applications conteneurisées en production. Il répond aux défis majeurs liés à la communication entre microservices : gestion fine du trafic, observabilité et résilience.
Les outils disponibles sur le marché ont atteint un niveau de maturité suffisant pour être adoptés. Ils peuvent être complétés dans le cas d’Istio par Kiali pour obtenir une visibilité détaillée des flux réseau.
La sécurité est un atout majeur dans Istio, notamment pour établir le chiffrement systématique en mTLS du trafic ou encore avec la mise en place de politiques de type Zero Trust portées par les AuthorizationPolicy.
Comme vous l’avez compris, Istio Ambient diminue l’empreinte CPU et mémoire comparé au Sidecar rendant l’installation d’un Service Mesh beaucoup moins consommateur et accessible pour des clusters conséquents avec de nombreux Pods.
De mon point de vue, adopter un Service Mesh n’est donc plus une option à long terme, mais un outil incontournable pour combler certaines limites de Kubernetes et exploiter sereinement ses applications en production.


